●流水线级数增加
总体上看,整数流水线部分,Athlon64(FX)具备12级流水线,相比K7的10级流水线增加了2级;浮点流水线部分,流水线深度则增加到17级,相比K7核心的15级增加了2级。
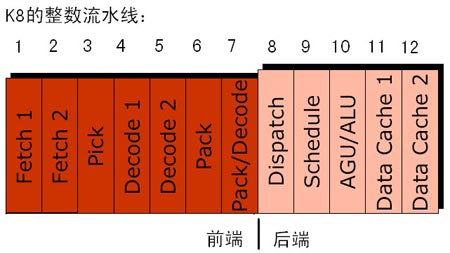

K8和K7的流水线
增加的流水线级数,显然有利于提升处理器的频率。然而相对P4的超长20级管线对提升处理器频率的贡献来说,Athlon64(FX)仍然较小,这也暗示了Athlon64(FX)处理器频率仍然将落下风的结局。不过幸好大家都已经清楚对于不同的处理器架构来说,处理器运行频率与实际性能之间并不存在简单的正比关系。
另外,还有一点要提的是:从许多资料上,大家可能会看到诸如K8流水线深度增加到32级之类的说法,这是由于加入了内部整合的内存控制器执行阶段。至于传统意义上的核心部分,流水线深度则应为12级和17级。
以下,我们顺着流水线的走向,来看看K8的核心部分与K7的异同之处。
●指令取和分支预测部分
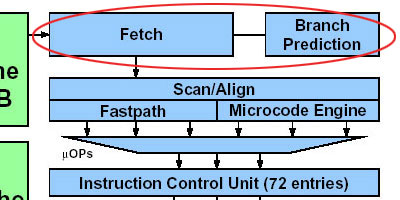
这部分的变化,主要在于分支预测单元部分所作出的改变。此部分许多媒体已经作了介绍,因此我们不再重复,只作简要说明。
由于流水线长度的增加,为了减小分支预测失败给处理器性能造成危害的可能性,K8相对于K7在其分支预测部分作出了一些改进,其中包括使用新的分支预测算法,将Global History Counter的条数增加到16K,为原来K7的4倍之多,加入可快速、准确地计算出下一条分支指令地址的Branch target address calculator等。通过这种改进,AMD宣称其分支预测精准度将比K7提高18%。
●解码部分
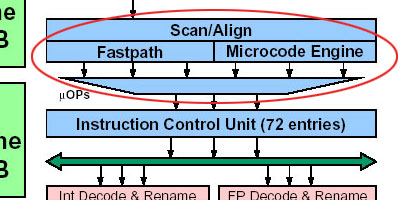
接下来,进入到解码部分。
解码部分的出口保持与K7一致,仍然为3个。不过,在K8的解码部分中,更多的指令将籍由硬件解码器(AMD称之为Fastpath或Directpath)而不是送往速度相对较慢的Mircocode单元中执行解码,比如原来需要借助Mircocode单元解码的SSE矢量数据处理指令,现在则完全由Fastpath单元担任解码工作,加强了执行SSE指令的处理效率。此外,由于K8处理器加入了对SSE2指令集的支持,很显然K8解码部分也因此相应作出了一些变化。
考虑到读者可能对Fastpath和Mircocode的概念比较陌生,这里我们对此进行一些解说:
我们都知道,要对一条X86指令进行解码,必须使用一些翻译机构。目前来看,使用的翻译机构不外乎两种:
一种是纯硬件的处理单元直接翻译,K8中的Fastpath指的就是这类单元;
另一种则是使用微编程(Microprogaming)的办法,将μOp(微指令)预先存储在MicroROM(MROM)内部,然后根据外部输入的指令来判定需要到MROM中选取那些μOp输出,K8中的Mircocode指的就是这类单元。
下面的图能帮助大家更好地理解这两种解码方式:
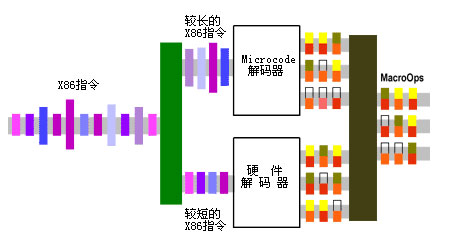
Fastpath和Mircocode解码原理图
两种办法互有优劣,纯硬件的解码器由于没有MROM的延迟问题,因此执行速度快,Fastpath也是因此而得名;但是,这需要相对复杂的硬件机构实现。特别对于X86这种复杂指令集而言,如果全部使用硬件处理单元直接翻译,势必导致解码处理单元数量的剧增;而Mircocode单元虽然从硬件上实施起来相对简单,同时很适合复杂指令集的口味,但是相对纯硬件的解码单元,存在延迟较大的缺点。
由于两者互有优劣,因此目前执行X86指令集的处理器解码单元中,通常都设置了这两种结构同时进行指令的解码翻译工作,通常由硬件解码器(Fastpath)负责包含μOp数目较少的短指令的解码,而由Microcode解码器负责包含μOp数目较多的长指令的解码。
●执行部分
接下来,经过解码的μOp,通过解码单元的3个出口顺着指令路径进入到处理器的发动机――执行部分。
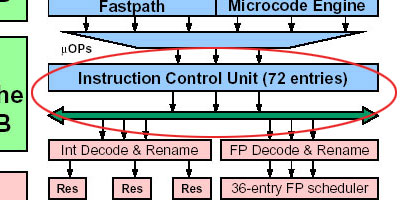
首先进入执行部分的ICU(指令控制单元),Intel又称ROB(微指令池)部分。此部分的任务是负责缓存由解码单元而来的μOp,协调它们输出到具体执行单元的顺序,负责处理执行过程中出现的异常情况等。在执行单元中担任十分重要的角色。不过,在K8中此部分参数基本没有变化,其所能容纳的μOp数目仍然保持为原来K7的72条。出口方面,显然也还是相同的3条出口。
由ICU出口处送出(Dispatch)的μOp(微操作),将视其类型分别送往浮点/多媒体指令执行部分或是整数/地址指令处理部分。
●指令调度部分
在执行部分中,MacroOp从ICU送出后,还要先送往浮点/多媒体指令执行单元或是整数/地址指令处理单元各自的指令调度器(Integer/FPU Scheduler)中进行进一步处理。
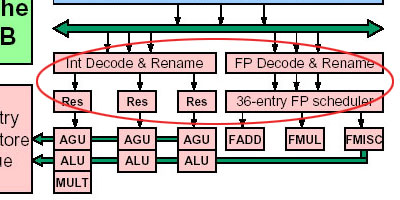
指令调度器对超标量处理器的执行效率意义重大,我们以整数/地址指令调度器(Integer Scheduler)―又称Reservation station(Res)为例,介绍指令调度器。它的工作大致可分以下三部分:
其一是负责在指令执行相对较慢的整数单元和指令送出(Dispatch)速度相对较快的ICU单元之间负责缓冲作用。其缓冲能力与指令调度器内部所能存放的μOp条目数(entries)成正比――单从这一点上看,与一、二级缓存的容量和其在处理器与内存之间所能起的缓冲作用的关系十分类似;
其二是负责将ICU送来的μOp,根据μOp的类型,将其分别送往(issue)AGU或ALU;
其三是根据存放操作数的寄存器以及AGU/ALU的空闲状况,负责安排好μOp送往AGU/ALU单元的次序。对于超标量处理器而言,指令的正确调度,对于避免出现流水线危机(Pipeline Hazard)的作用十分重大。
在K8中,为了加强整数部分的性能,该部分所用的指令调度器所能缓冲的μOp条目数由原来的18条增加到了24条。增加整数指令调度器的μOp条目数,显然是当心较慢的整数执行单元或是频繁使用的寄存器会使前面发布μOp的ICU陷入等待状态。
●整数执行单元和浮点/多媒体指令执行单元
接下来,指令进入整数执行单元或浮点/多媒体指令执行单元。
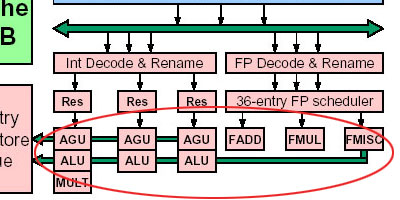
整数处理单元仍然由3个AGU、3个ALU组成。不过,在执行整数乘法时,K8核心的整数乘法单元(MULT)在处理32位整数数据乘法操作时,延迟由K7的4个周期减小为3个周期,具体如下表:

改进的整数乘法执行效率
浮点/多媒体指令执行单元部分则基本没有变化,仍然是原来的FADD、FMUL以及FMISC三个部分。强大的浮点单元应该令AMD感到十分放心。
不过对于多媒体指令特别是新增的SSE2指令处理方面,在执行阶段,可以说基本同K7不会有什么太大的区别,这方面唯一的改进,应该在我们刚才提及的解码部分,加快了这类指令的解码速度。
以上我们粗略为大家介绍了K8处理器核心部分的改进。希望对大家理解新的K8核心能起到一定的参考作用。
 相关经销商
相关经销商




 文章搜索
文章搜索 热门文章
热门文章
