Athlon64――为你朝思暮想
关心AMD的人应该知道,AMD公司旧有的K7处理器Barton、Athlon XP由于EV6前端总线带宽、处理器核心频率提升能力不足等问题,在性能表现上不及Intel P4系列。
AMD要想在性能上同Intel继续竞争,必须依靠新的前端总线和处理器核心。为此,AM
D公司早在3年前就放出新研制的K8核心处理器及其搭配的X86-64指令集的消息。
在这3年漫长的等待过程中,有关AMD公司产能有限,将被IBM兼并;AMD应用SOI技术制作新K8处理器时出现问题等流言通过各路媒介四处传播开来。终于在2003年9月中旬,继推出服务器平台的K8核心Opteron处理器系列之后,AMD排除万难推出了万众瞩目的AMD Athlon 64 FX51(支持双通道DDR400)和AMD Athlon 64(仅支持单通道DDR400)两个系列的桌面处理器,用事实给那些流言制造者们砸下了重重的一锤。
另一方面,针对Athlon 64系列的推出,Intel慌忙在2003年秋季的IDF论坛拿出了具备多达2MB三级缓存容量的P4 3.2GHz Exterem Edition处理器作为应对。稍加注意我们就可以发现,P4 EE同Intel的另一款支持多处理器系统的服务器CPU――Gallatin核心的Xeon MP规格非常相像,甚至可以说是Xeon MP去掉对多处理器支持的简化版。由此看来,为了对付Athlon 64系列,Intel可谓煞费苦心。
那么,让我们苦苦等待,迫使Intel不惜出动“服务器级“处理器大动干戈的Athlon 64系列究竟有哪些新看点呢?接下来,我们就在此为大家做一番详尽分析。
X86-64分析(一):我拥有你,但未必幸福
说到K8处理器,大家不免会想到AMD大肆宣传的X86-64指令集的概念。而要较为明晰地理解X86-64指令集,就必须从64位处理器的本质谈起。
●理解64位指令
我们都知道,处理器所处理的普通指令一般由操作码(OP Code)和操作数(Operand)组成。其中操作数可以是等待处理的数据,也可以是待处理数据的内存地址。而操作码则描述将要对操作数进行何种处理。
需要强调的是,通常所说的64位指令,并不是指指令的全长或操作码的长度为64位,而是指操作数所能达到的最大位数为64位。通过下面的图示,我们可以很好地理解64位指令和64位处理器的本质。
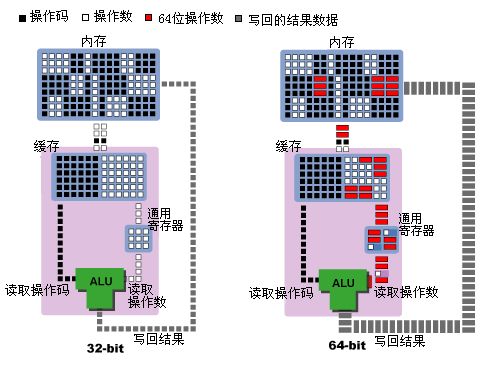
64位指令工作原理示意图
由于操作数一般需要存放在通用寄存器中,因此64位处理器通用寄存器的尺寸也必须是64位。这样我们就很容易理解K8处理器里通用寄存器结构的上半部分(指RAX-RSP部分,下半部分我们后边再提)。如下图所示:
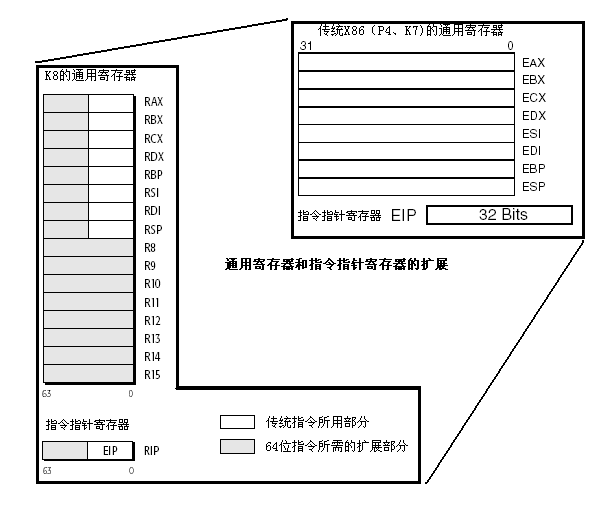
K8通用寄存器的扩展
从上面的图示可以看出,相对于传统的X86处理器而言,K8在进行64位扩展的时侯,把8个通用寄存器增加到了64位,同时增加了指令指针寄存器的位数为64位。
至于寻址方面,由于地址数据只不过是整数操作数中的一种,因此同样使用GPR。这样,64位处理器所能处理的地址数据长度自然就增加到了64位,从而大大增加了处理器的寻址空间。
当然,为了简化起见,以上我们所说的操作数,只不过是现代CPU所处理的操作数中的整数数据(地址数据)。它们由处理器中的ALU(算术逻辑单元)和AGU(地址生成单元)进行处理,一般使用通用寄存器(GPR)来保存。实际上,我们还需要处理通常保存在浮点寄存器、MMX以及XMM寄存器里的浮点以及其它多种数据。
不过,在我们进一步谈这些除了整数和地址数据外其它数据类型在64位处理器中的处理状况前,我们必须首先了解一些有关寄存器和数据类型的基本知识。
●寄存器和数据类型
我们知道:整数、地址、指令指针和浮点数据是按照数据形式来划分的,CPU所要处理的3种主要数据类型。此外我们还可以根据数据需要CPU进行处理的类型,来将它们分为标量数据和矢量数据两大类。
通常我们把需要CPU进行不同处理的单个数据称为标量数据(Scala Data)。标量数据既可以是整数数据,也可以是浮点数据。其中整数标量数据的存放区一般为通用寄存器(GPR),浮点标量数据的存放区一般为浮点寄存器(FPR)。
与标量数据相对的是矢量数据(Vector Data)。所谓矢量数据就是指一列需要由处理器作相同处理的数据集合。比如处理器在做MP3编码的过程中,需要对内存中的音频文件里的各字节数据作相同的MP3编码操作。那么通常使用MMX或SSE这类单指令多数据流(SIMD)指令,将数个字节打包为一组矢量数据,存放在MMX或SSE寄存器中,再送往相应的功能单元进行统一操作。
和标量数据一样,这些矢量数据既可以是整数数据,也可以是浮点数据。矢量数据以封包的形式批量存放在MMX(对于使用MMX、3DNow!进行操作的数据而言)和XMM(对于使用SSE、SSE2进行操作的数据而言)寄存器中。
通过下面的图,我们可以更好地了解标量数据和矢量数据的区别:
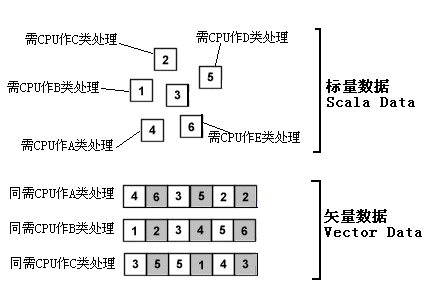
标量与矢量数据
我们整理了标量数据和矢量数据在X86-32位处理器以及AMD的X86-64处理器中所用寄存器的具体区别如下表:
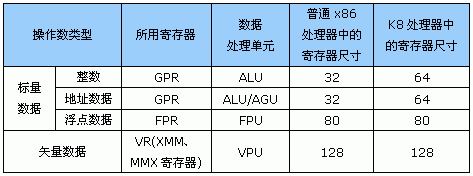
实际上,MMX和XMM通过寄存器映射的方法,也可以参与标量浮点数据的存储。同时数据类型也远不止整数、浮点这两类基本数据类型,还包括有指令指针数据、BCD数据,位数据等。要把这些情况一一说清,显然不是一两篇文章能解决得了问题的。
幸好,这些省略的部分与我们的结论并没有影响,因此我们叙述时使用了简化的措施。需要更详细完整的资料,您可以参考Intel的IA32以及AMD的X86-64架构编程指导书。
从上表我们可以看见,K8的64位扩展部分似乎仅对于整数、地址数据有效。对浮点和向量数据则仍然保持原样。
经过上面的分析,我们似乎可以得出这样的结论,那就是:我们能从K8向64位的扩展所获得的好处,只不过是可以在同样一条指令中,处理更大数值的整数数值以及管理空间更大的内存区域而已。而在32位的情况下,由于通用寄存器只能容纳最大32位的数据,因此显然要花费更多条指令对尺寸超过32位的数据进行处理。
这种改进对服务器、科学计算这样的领域虽然具有一定的意义,但显然并不是普通家用环境急需的改进。试问在近期普通应用中,有多少情况下会用到超过232这样大的整数数值和超过4GB的内存空间呢?
然而,如果你因此低估了K8和X86-64指令集的实力,那就大错特错了。
 相关经销商
相关经销商




 文章搜索
文章搜索 热门文章
热门文章
