参数系统对比测试:ScienceMark 2.0
接下来,我们使用另一个常用的测试工具:ScienceMark 2.0来测试两个系统的内存子系统性能,以下是测试的详细结果:
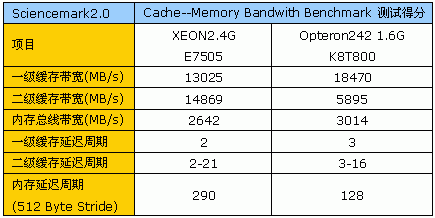
测试结果可见,尽管Opteron242一级缓存运行频率较低,但在带宽方面仍然胜过Xeon的一级缓存,领先程度达到40%左右,优势明显。
而到了二级缓存这边,情况则完全反过来,我们认为,Opteron二级缓存带宽性能的低下与其运行频率、接口位宽仅128bit为Xeon的一半不无关系。
最后,是内存带宽、延迟的较量,我们可以看到,即使使用的是妥协的方案,Opteron系统的相关参数仍然具备显著的领先优势。同时我们也必须注意到,使用妥协方案后,由于其中一个处理器需要经过Hypertransport总线访问内存,因此双Opteron内存延迟周期参数将有所下降,相比单处理器的情况,延迟增加6个总线周期左右。
参数系统对比测试:Linpack
Linpack测试是一种使用尺寸由小到大的浮点矩阵乘法计算来考核处理器标量浮点性能以及缓存、内存系统带宽、延迟性能的测试工具,主要用于分析缓存、内存系统性能。由于源码开放,因此受到许多测试的青睐。其支持多处理器的高级版本更是成为衡量超级计算机性能的权威工具。
我们使用的是Aceshardware的Linpack软件包进行测试,该软件包是征对Windows系统使用Linpack库文件重新编译的,由于只是一个简化的版本,因此不支持多处理器。但仍不失为一种为评价处理器性能提供参考的有力工具。以下为测试结果曲线图:
6款处理器的Linpack测试结果图(点击察看全图)
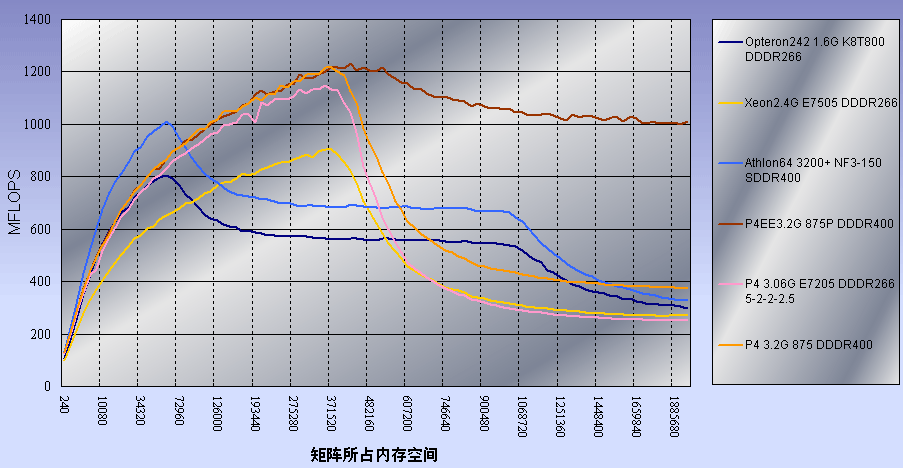
测试结果图中,纵坐标为测得的MFLOPS数(百万浮点计算次数/秒),而横坐标则为计算的矩阵尺寸大小。
为了让大家更好地理解Linpack软件测试,我们共使用了6款CPU进行测试。测试结果图中如无特别说明,则内存时序均为6-3-3-2.5。
由测试结果曲线我们可以看到:
◎ 在曲线的前段,由于此时矩阵尺寸较小,因此主要考核一级缓存的延迟和带宽性能;
◎ 而随着矩阵尺寸的增大,逐渐超过了K8的64KB一级数据缓存容量之后,处理器的MFLOPS出现第一次下降,这是由于此时计算所需要的数据已经无法被一级缓存所完全容纳,因此处理器必需到速度稍慢的二级缓存中读取,故此MFLOPS的成绩受到前端带宽不足的影响而开始下降;
◎ 最后,当矩阵尺寸进一步增大到超出二级缓存+一级缓存的容量(由于AMD处理器一直使用Exclusive的缓存结构,因此其缓存总容量应为二级缓存+一级缓存,对于Opteron,这个值是1064KB左右)时,处理器将不得不到速度更慢的内存中读取,因此出现第二轮MFLOPS的下降。这里由于Athlon64 3200+使用了DDR400内存,运行频率又较高,因此Linpack性能优于Opteron242。
而到了Intel P4以及Xeon这边,我们看到的,则是另一种形状的曲线。
◎ 相对于K8来说,在曲线图的前部,尽管运行频率较高,但由于一级缓存容量较小,因此其一级缓存效率似乎不及K8,即使是象P4EE 3.2G这样变态级的处理器,曲线前段也仅与1.6G的Opteron242持平;
◎ 但是到了体现二级缓存效率的曲线图中部这里,Intel的Netbuster体系则凭借频率、数据传输位宽较高,延迟较小的二级缓存获得了不小的优势。
◎ 不过,由于容量仅512KB,所以当矩阵尺寸超出其二级缓存容量的512KB左右时(由于Intel处理器一直使用共享式的缓存结构,因此其缓存总容量应为二级缓存或三级缓存的容量,对于2.4G的XEON,这个值是512KB左右),由于需要到内存中取数据,而P4、Xeon的内存子系统性能又不及K8,因此在曲线图的后部一路落后下去,同时由于在曲线图后部的前半段,Opteron可以从1064KB的总缓存容量中得益,因此领先幅度更大。
不过这里P4EE得益于2MB超大容量的L3 Cache,取得了惊人的成绩,MFLOPS数目一度高居1000以上!可以说是遥遥领先了。但应该注意到的是,由于这个Linkpack测试的最大矩阵所占内存容量仅1.9MB左右,没有超出P4EE的2MB L3 Cache容量,假使我们继续增大矩阵尺寸,P4EE曲线仍会迅速回落到P4体系应有的水平。
此外,由于P4 3.2GHz使用了双通道DDR400,因此在曲线图的后部领先也并不奇怪了。
同时,在曲线图中与Xeon 2.4G同为533MHz前端总线的P4 3.06G,虽然使用的内存时序参数高出Xeon2.4G不少,却仍在曲线后部落后Xeon,这应该是体现了各自的北桥芯片组内存管理效率上的不同了。
在Linpack测试中,考验标量浮点数据性能的前半段曲线特性,为K8浮点处理单元的高超性能提供了又一个有力的证据。
 相关经销商
相关经销商




 文章搜索
文章搜索 热门文章
热门文章
